Spark Shuffle流程

文章目录
shuffle可以分为shuffle write和shuffle read两个阶段,执行shuffle write的称为map端,执行shuffle read的称为reduce端,下面分别看一下这两个阶段spark是如何处理的。
shuffle write
shuffle write阶段有三种不同的模式,适配不同的情况。
bypass shuffle write
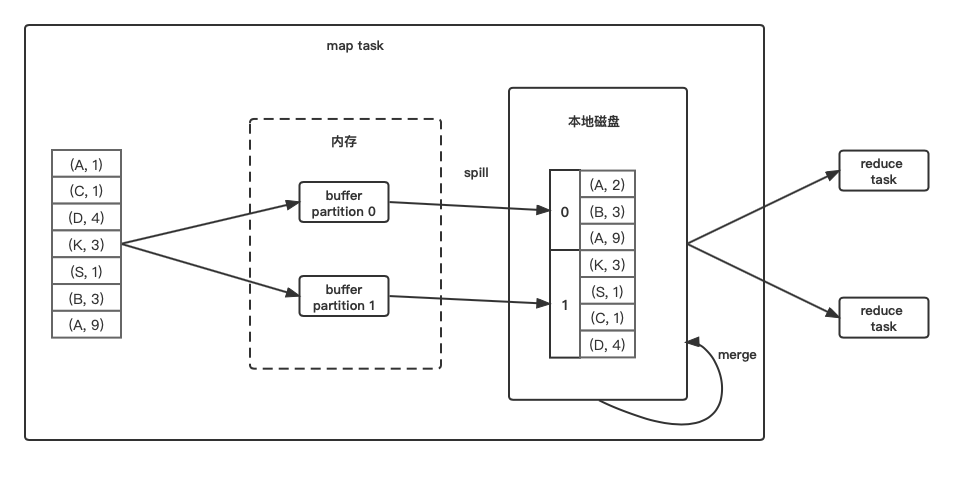
最简单粗暴的一种方式,依次读数据,计算其partitionId,根据partitionId输出到不同的buffer中去,每一个buffer对应一个磁盘上的分区文件,当buffer满了之后,spill到对应的分区文件中,最后将多个分区文件,合并为一个数据文件,并生成一个索引文件来记录分区位置(之后shuffle write每种模式,最终都会合并成一个数据文件和一个索引文件)。
- 优点: 速度快
- 缺点: 当reduce端的task数过多时,会生成大量的buffer,导致占用内存增多,要维护多个打开文件。
- 适合的操作类型: map端不需要combine,分区数较少(默认情况下,reduce task数要小于200个),如groupByKey,ParitionByKey,sortByKey等。
sort shuffle write
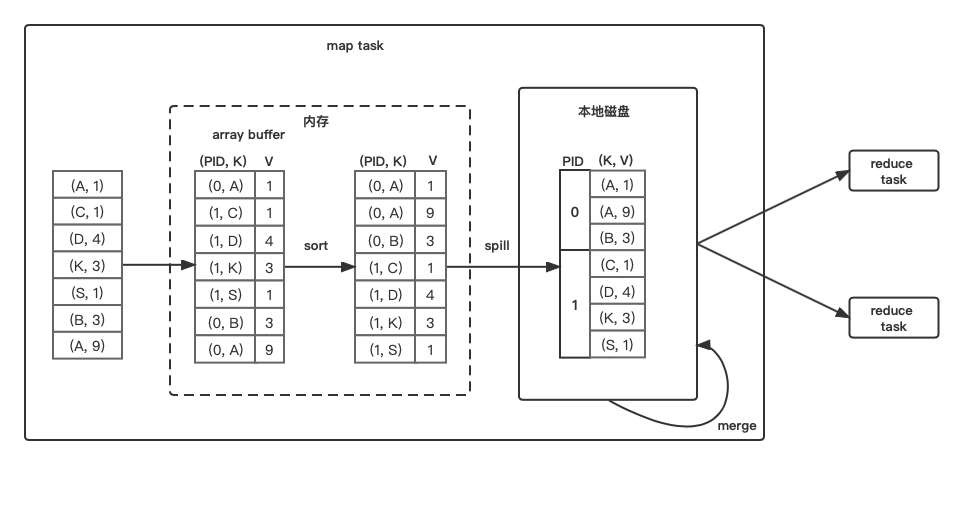
依次读数据,计算其partitionId(PID),将PID和数据丢到array buffer中去,当array达到阈值后,根据(PID, KEY)对array中的数据进行排序,然后将排序的结果spill到磁盘中,当数据全部处理完成后,会到很多内部排好序的磁盘文件,将这些文件中的数据进行一个全局排序后,会得到一个数据文件和索引文件。
- 优点: 相对于bypass来说,可以大大减少建立和打开文件数,减少buffer占用的内存资源。
- 缺点: 排序比较耗时。
- 合适的操作类型: 其实是万金油,但如果map端需要combine,则需要使用第三种模式。
- 备注: 当map端的key不需要排序时,仅通过对PID进行排序也可以完成sort shuffle。
sort shuffle(combine) write
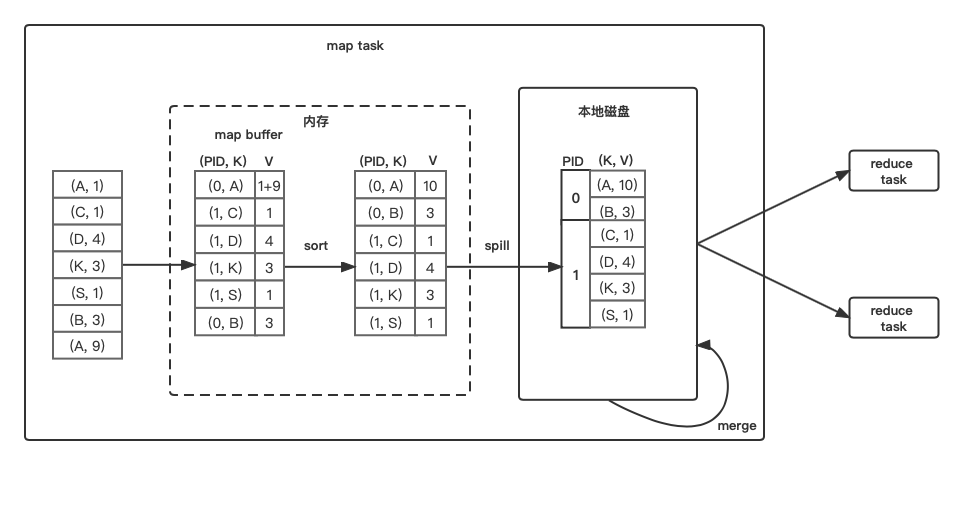
依次读数据,计算其partitionId(PID),将其丢一个有序的map(PartitionedAppendOnlyMap)中,在线聚合(边捞数据边聚合),当Map达到阈值后,根据(PID, KEY)对array中的数据进行排序,然后将排序的结果spill到磁盘中,最后将内部排好序的文件进行一个全局排序后,会得到一个数据文件和索引文件。
- 优点: combine操作可以大大减少最后shuffle后数据的大小。
- 缺点: 排序比较耗时。
- 适合的操作类型: 仅适合于map端需要combine的操作,如reduceByKey、aggregateByKey()等。
shuffle read
不需要combine和sort
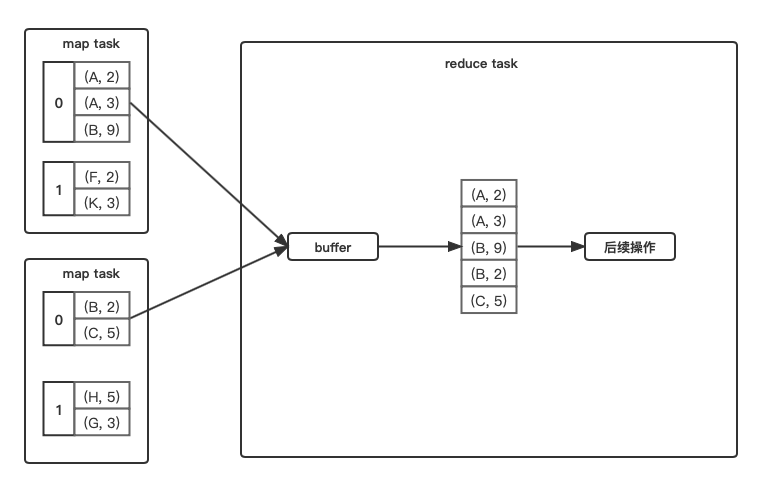
简单粗暴,直接从各个map task获取数据,塞到buffer,之后的操作直接从buffer中拿数据。
- 合适的操作类型: partitionBy()等。
需要sort
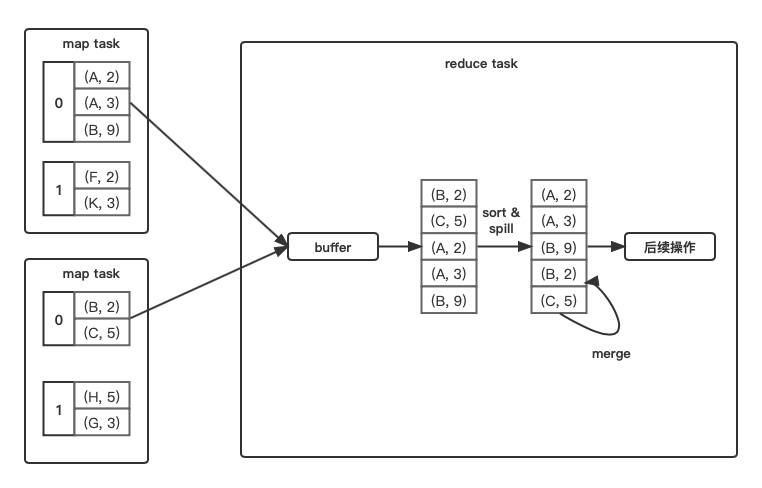
和sort shuffle write的流程几乎一致,在buffer里排序,spill到磁盘,merge磁盘文件,只不过不用分区,所以不用计算partitionId,也不会生成索引文件。
- 适合的操作类型: sortBy()、sortByKey()等。
需要combine
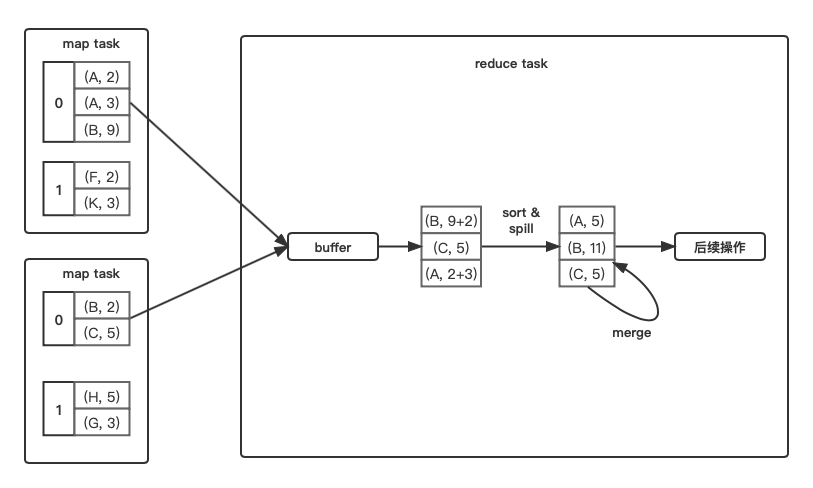
和sort shuffle write(combine)的流程几乎一致,在buffer里实时聚合,然后sort并且spill到磁盘,merge磁盘文件,只不过不用分区,所以不用计算partitionId,也不会生成索引文件。
- 适合的操作类型: reduceByKey()等。
备注
- 其实shuffle read阶段,没有优缺点的问题,而是有些操作只能这么做。而且除了像partitionBy()这样单纯分区的操作,大多数的操作都需要排序,如果不排序,一旦数据spill到磁盘,你咋从多个无序数据的磁盘文件,去做combine啥的,重新全部搞到内存里吗?(可能个人理解有误)
结语
因为直接看的书和文档,没有去扣代码,有不对的地方,还请指正,感谢。
引用、参考
文章作者 libra
上次更新 2022-04-01