Spark运行架构

文章目录
运行架构
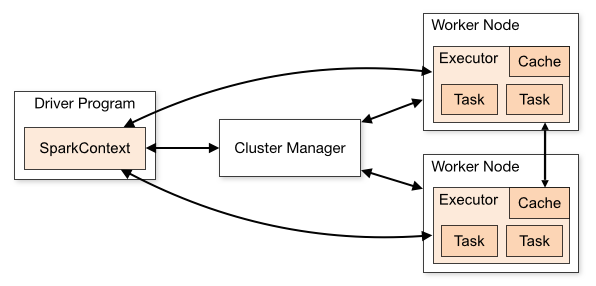
上图是在spark官方上找的图,这里我们只说上面几个块块是做什么用的。
- Driver Program,为Spark的驱动程序,其实就是一个spark任务的main函数产生的进程,创建SparkContext。SparkContext会声明rdd的transformation和action,并与Cluster Manger和Worker Node交互,完成计算任务。
- Cluster Manager,获取集群资源的外部服务(如Standalone、Yarn、k8s),用来申请资源,调度Woker Node。
- Worker Node,工作节点,负责Executor的启停和观察Executor的运行情况。
- Executor,Spark执行器,是Spark计算资源的一个单位,Spark先以Executor为单位占用资源,然后再将具体的任务分配给Executor执行。Executor在物理上就是一个JVM进程,可以起多个线程执行计算任务(Task)。
- Cache,Executor进程的缓存。
- Task,Spark的计算任务,是spark中最小的计算单位,不能再拆分。执行具体的计算任务,如map、reduce算子。
一个spark任务执行任务过程,大概如下:
- SparkContext划分Job、Stage,向Cluster Manager申请计算资源。
- 申请到的Worker Node,将会创建需要的Executor。
- Executor执行具体的计算任务。
宽依赖和窄依赖
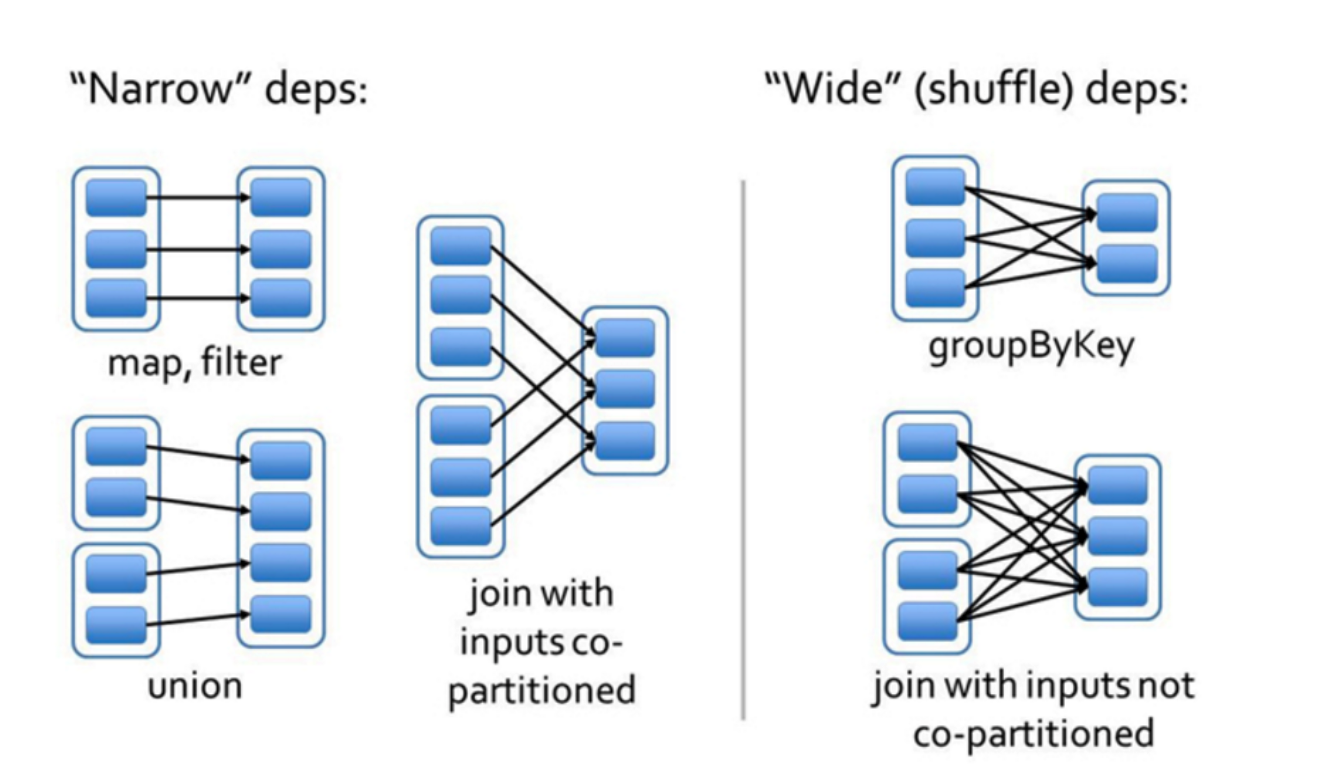
父RDD中每一块分区中的数据经过重新分区(shuffle)后分发到子RDD各个分区的操作就是宽依赖(ShuffleDependency or WideDependency),否则就是窄依赖(NarrowDependency),就是这么简单。
备注
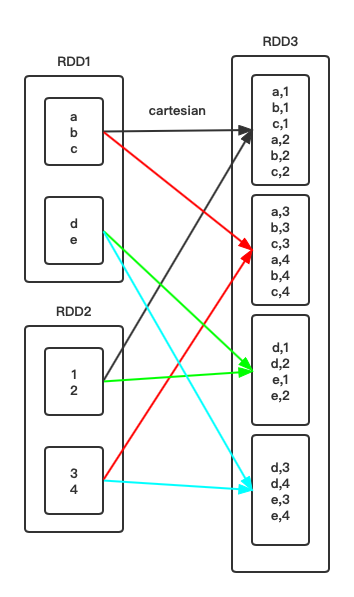
有一个比较混淆的点,就是cartesian()算子,每一个子RDD分区是依赖父RDD分区的全部数据,一个父RDD每个分区数据完整分发给多个子RDD分区,但没有经过shuffle,所以它还是属于窄依赖(NarrowDependency)。
物理执行计划
Spark具体使用三个步骤来生成物理执行计划。
-
根据action操作顺序将应用划分为作业(job)
我们知道spark只有出现action操作时,transform算子的计算逻辑才能真正的执行,也就表示应用会生成一个job,该job的逻辑流程包括从数据的输入到最后的action操作。如果应用程序中有很多action()操作,spark会按照顺序为每个action()操作生成一个job。
-
根据ShuffleDependency依赖关系将作业(job)划分为阶段(stage)
对于每一个job,初始化一个stage,该stage包含最后一个rdd,然后从最后一个rdd向前推,如果当前rdd与其parent rdd的依赖关系为NarrowDependency(窄依赖),将其parent rdd容纳进该stage,继续向前推;如果为ShuffleDependency(宽依赖),当前stage结束,初始化一个包含其parent rdd的新stage,继续想前推;
-
根据分区计算将阶段(stage)划分为计算任务(task)
由于每个stage内部的算子都是NarrowDependency,所以每个分区的数据可以独立计算,不依赖其它分区的数据,spark根据stage最后一个rdd的分区数来决定task的数量,如果该stage最后一个rdd有5个分区,那么该stage就生成5个task。
来举一个具体的例子,代码如下。
|
|
我们根据上面三个步骤,来推一下这段代码的物理执行计划。
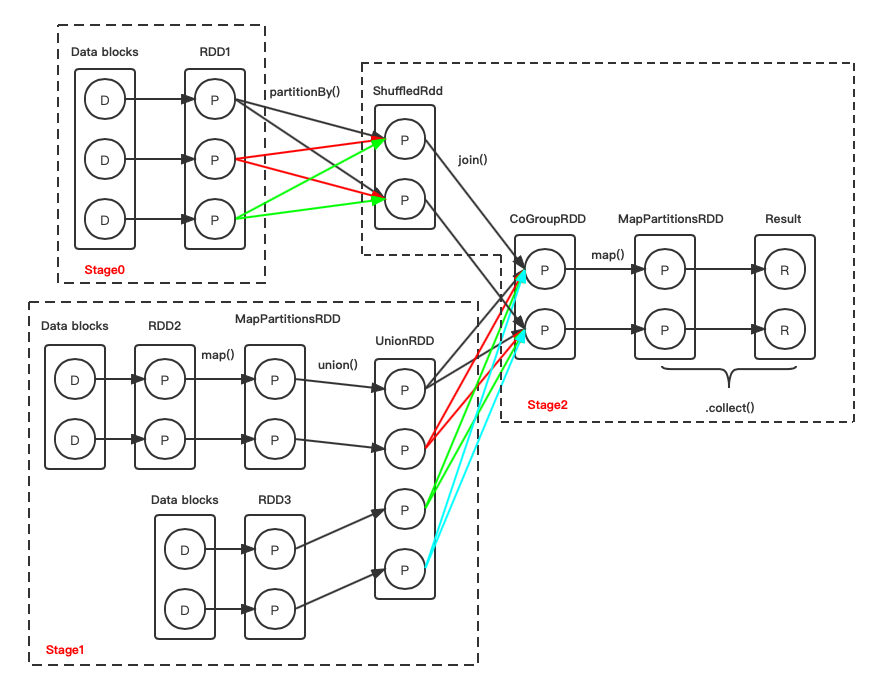
- 首先
mapCogroupRdd.collect是一个action算子,所以将其之前的一系列操作作为一个job。 - 从mapCogroupRdd向前推,一共有两次shuffle操作,分别是
rdd1.partitionBy(new HashPartitioner(2))、shuffledRdd.join(unionRdd),所以将此job划分为三个阶段。 - stage0最后一个rdd的分区数为3,所以stage0分配的task数也为3,其余stage同理,stage1的task数为4,stage2的task数为2。
我们运行上面的代码,通过spark UI来验证一下上述推断是否正确。
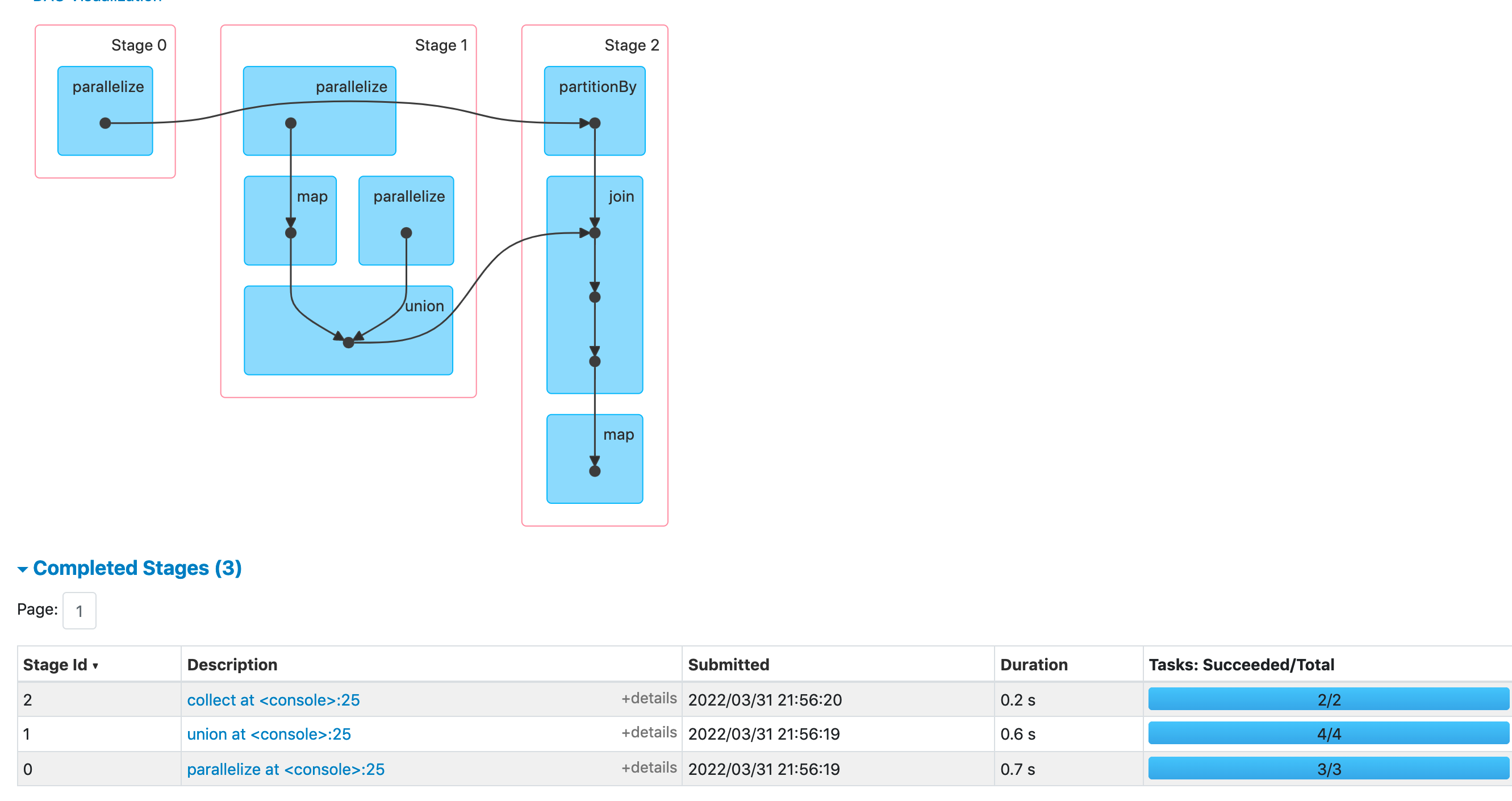
可以看到是与推断一致的(之前我使用python去生成相同的job时,由于python到jvm还会进行一些数据的转换,导致spark UI上展示的执行计划会有些出入)。
备注
-
当cpu资源足够时,没有前后依赖的stage可以并行执行,如stage0、stage1可以同时进行计算,但stage2必须等待stage0、stage1都完成后才可以开始计算。 同一个stage里的task没有依赖关系,可以并行计算。
-
同一stage中,大多数常用的NarrowDependency算子都是一一对应的数据依赖关系,可以一条一条进行流水线计算,节省大量的内存。
-
ShuffleDependency需要将数据进行重新分区,在多Executor情况下,一定会通过网络传输数据,部分多对一和多对多的NarrowDependency也会通过网络传输数据(网上流传的"窄依赖一定不走网络"的说法是错的)。
结语
spark shuffle的过程会单独写一篇。
引用、参考
文章作者 libra
上次更新 2022-03-29