Postgresql-VACUUM干了些啥?

文章目录
VACUUM最主要作用是回收dead tuples所占据的存储空间,所以我们需要先了解一下postgres是如何存储数据的,什么样的操作会出现dead tuples.
数据存储
这里只介绍堆表数据的存储,其他索引数据暂不展开介绍。
页(Page)结构
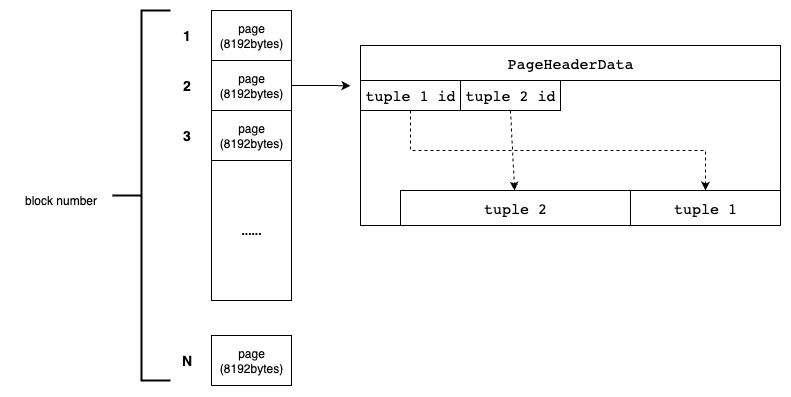
数据文件内部被划分为固定长度的页,也可以叫区块,每个页的大小默认为8kb,每个文件中的页编号从0开始,如果页被填满了,则在文件底层新开一个页。
页包含三种类型的数据:
- 堆元组,也就是图中的
tuple 1、tuple 2,这就是数据本身,它们从页的底部开始堆叠,下面会介绍元组内部的数据结构。 - 行指针,也就是图中的
tuple 1 id、tuple 2 id,每个指针4B,指向堆元组,扮演元组索引的角色。 - 头部数据,记录关于页面的元数据,这里不详细介绍,官方文档链接: postgresql-storage-page-layout
行指针的末尾(tuple 2 id)与最新元组(tuple 2)起始位置之间的空余空间称为空闲空间,通过这段空间来判断下次新增数据需不需要新开一个页。
为了识别表中的元组,数据库内部会使用元组标识符(tuple identifier,TID)来表示数据的位置,TID由两个值组成,分别是元组所属页面的区块号和指向元组的行指针的偏移号,比如(10, 2)表示在第十个页上的第2个元组,其余索引通过记录TID来获取原数据。
另外,通常当元组大小超过2kb时,postgres会使用TOAST方法来存储这种元组,简单来说,会将较大元组数据单独存储,会在堆元组数据记录一个指向它的指针,官方文档链接: storage-toast。
元组(Tuple)结构

堆元组包含三个部分数据:
-
HeapTupleHeaderData,保存该元组的一些元数据,这里我们只需要了解一下四个字段就可以了,更多的可以参考官方文档: postgresql-storage-row-layout
- t_xmin,保存插入该元组的事务ID。
- t_xmax,保存删除或更新此元组的事务的 txid。如果尚未删除或更新此元组,则t_xmax设置为0,即该元组依然有效,没有被删除。
- t_cid,保存命令标识,记录执行当前命令之前该事务执行了多少SQL命令。假如一个事务执行了以下操作
BEGIN;INSERT A;UPDATE A;INSERT B;COMMIT;,该元组是再执行INSERT B时创建的,那么cid为2。 - t_ctid,保存指向自身或者新元组的tid,在更新该元组时,t_ctid 会指向新版本的元组(这个需要配合后面
数据的更新流程去理解)。
-
空值位图,标记该数据是否为null。
-
用户数据,用户实际要存的数据。
元组的插入、更新、删除操作
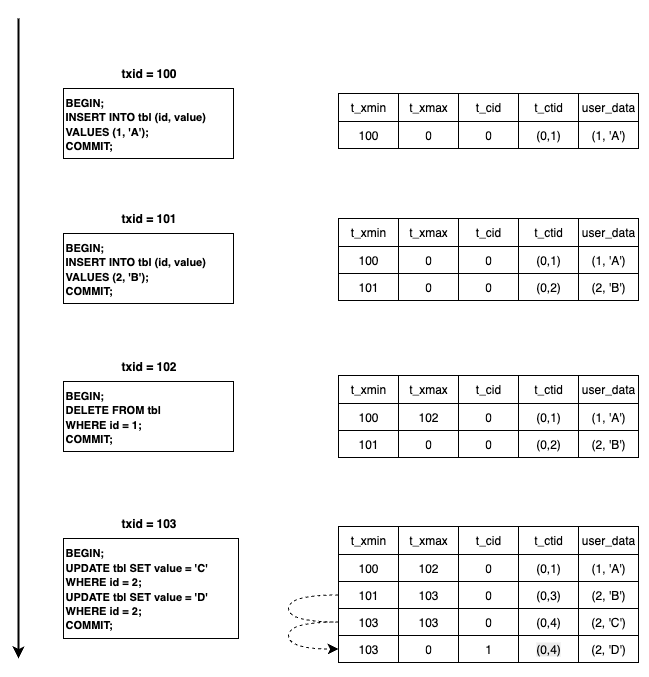
表定义:
|
|
假设以下操作均没有跨页,t_ctid第一个值总为0。
插入
第一步,事务100插入了一条数据。
- t_xmin设为100,该元组由事务100插入的。
- t_xmax设为0,该元组没有被删除或更新。
- t_cid设为0,该元组是由事务100的第一条命令插入的。
- t_ctid,设为(0,1),指向自身,因为这是该元组的最新版本。
第二步,事务101与事务100同理,不再赘述。
删除
第三步,事务102删除id=1的数据。
- 逻辑删除,将t_xmax设为102,t_xmax不为0,说明该元组为死元组(dead tuple)。
- 其他字段不变。
更新
第四步,事务103进行了两次更新操作。postgres更新的操作逻辑为删除旧元组并插入一条新元组。
第一个更新操作。
Tuple 2(表中第二行数据):
- t_xmax设为103,逻辑删除。
- t_ctid设为(0,3),指向新插入的元组。
Tuple 3(表中第三行数据):
- t_xmin设为103,该元组由事务103插入的。
- t_xmax设为0,该元组没有被删除或更新。
- t_cid设为0,该元组是由事务103的第一条命令插入的。
- t_ctid,设为(0,3),指向自身,因为这是该元组的最新版本。(由于后面该元组会被继续更新,图中没有展示这一中间过程)
第二个更新操作。
Tuple 3(表中第三行数据):
- t_xmax设为103,逻辑删除。
- t_ctid设为(0,4),指向新插入的元组。
Tuple 4(表中第四行数据):
- t_xmin设为103,该元组由事务103插入的。
- t_xmax设为0,该元组没有被删除或更新。
- t_cid设为1,该元组是由事务103的第二条命令插入的。
- t_ctid,设为(0,4),指向自身,因为这是该元组的最新版本。
Vacuum的流程
|
|
vacuum流程大致可以分为三大部分。
- 定位和收集死元组(dead tuple)的位置。
- 移除死元组(dead tuple),调整page layout,更新FSM(Free Space Map)和VM(Visibility Map)。
- 更新系统元数据和统计信息。
扫描
在扫描表的所有数据页时,系统会收集其中的死元组,并将它们存放在内存列表中。该列表的大小受 maintenance_work_mem 参数限制。
如果列表超出内存限制且仍有数据页未完成扫描,系统会先清理列表中已有的死元组,然后继续扫描剩余的数据页,直到完成全表扫描。
由于全表扫描的代价较高,PostgreSQL 引入了 Visibility Map (VM) 来降低开销。 VM 用于标记数据页中是否存在死元组,扫描时可根据 VM 判断该页是否需要跳过,从而避免不必要的读取。 VM官方文档: storage-vm
清理
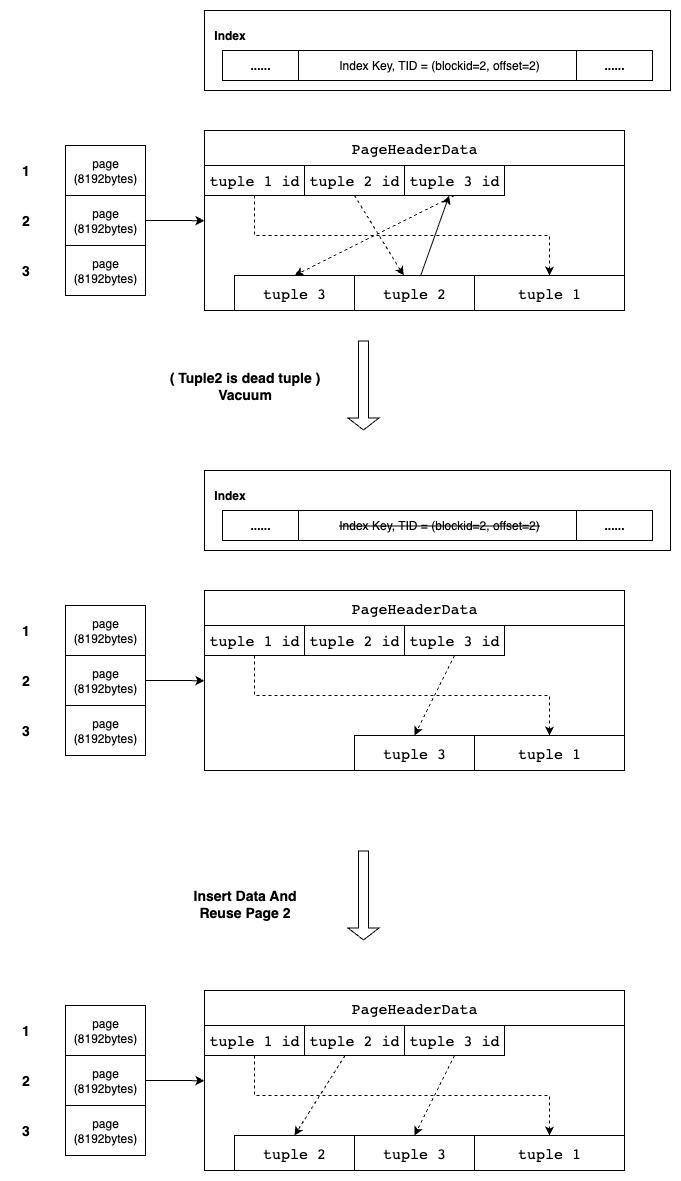
图中有两步操作,其中第一步操作属于vacuum部分,第二步操作属于重用page空间的部分,这里顺带画出来了。
正式清理死元组。
- 死元组(如 tuple2)被移除,剩余元组在 Page 中重新排列,并更新对应的行指针。
- 行指针 tuple2 会被保留,仅标记为无效,以避免影响其他元组的 TID。
- 页的物理大小保持不变,因此普通 Vacuum 不会减少磁盘文件大小。
更新VM和FSM,死元组被清理后,页面会产生可回收的空闲空间。Postgres 会通过 FSM(Free Space Map) 记录各个页面的可用空间大小。当有新元组写入时,Postgres 会优先查询 FSM,尝试将新数据放入已有的空闲页面,而不是总是追加到新页中。
FSM官方文档: storage-fsm
更新统计信息
更新与清理过程相关的统计信息和系统视图,这些统计信息会被查询优化器使用,这里就不详细介绍了。
关于Vacuum Full
在前文的介绍中我们知道,普通 VACUUM 只会在数据页内部进行清理,不会真正删除数据页,因此无法回收磁盘空间。 为了彻底回收空间,PostgreSQL 提供了 VACUUM FULL 命令。
VACUUM FULL 的本质是 重建表:系统会创建一个新的表,将旧表中的存活数据复制过去,然后用新表替换旧表,并删除旧表。
这样可以真正释放磁盘空间,但缺点也很明显:执行过程中需要锁表,如果表数据量很大,执行时间可能会很长,影响业务。
为解决这个问题,官方推荐使用扩展 pg_repack,它能在几乎不锁表的情况下实现类似 VACUUM FULL 的效果。 其原理是:在复制旧表数据到新表的过程中,pg_repack 会创建一个触发器,用于捕获此期间所有对旧表的修改,并记录到日志表中。
当数据复制完成后,系统会逐步重放日志,保证新表与旧表的数据一致。
最后只在剩余少量日志需要同步时,进行一次短暂的锁表操作完成日志重放和表替换,从而将锁表时间降到最短。
参考
文章作者 libra
上次更新 2025-09-11