Mapreduce流程

文章目录
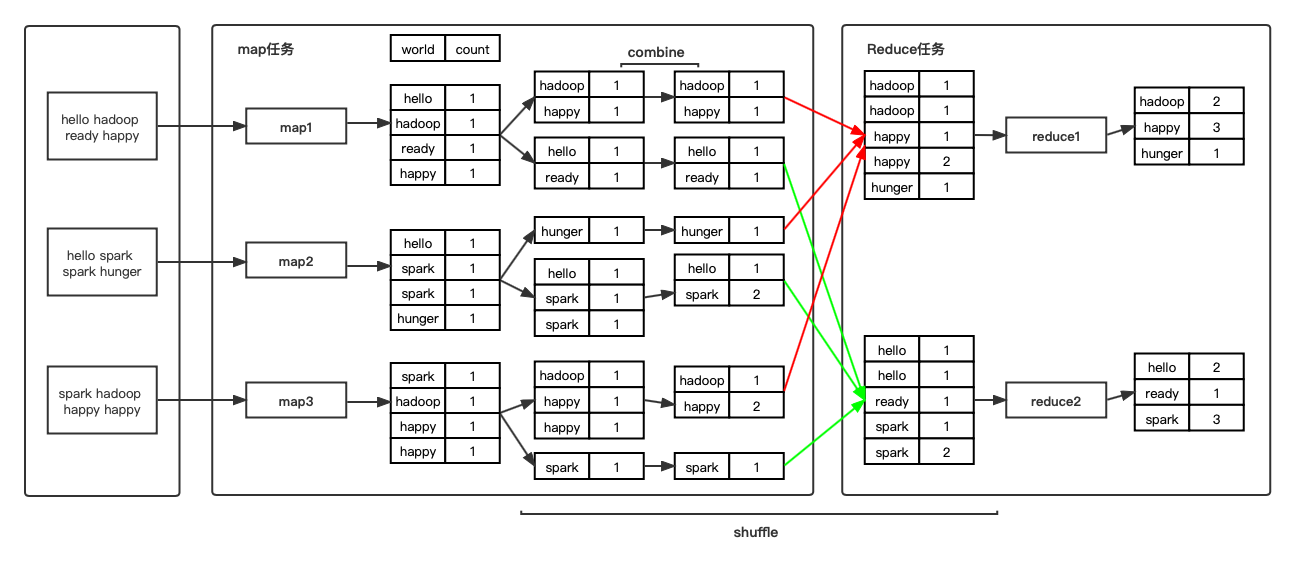
执行过程
假设mapreduce任务有M个Map任务和R个Reduce任务。
Map阶段:
- input: 在进行map计算前,mapreduce会根据数据的分布情况,将数据分为M个块,每一个数据块对应一个map任务。
- map: 每一个map任务读取对应的数据块的数据进行计算。
- partition: shuffle阶段开始,根据计算结果的key值进行hash分为R份(与Reduce任务数一致)。
- spill: 分为sort和combine两步,之后写到磁盘中多个临时文件中,多个临时文件最终会合并为一个文件,会有索引来标记文件各部分属于哪个分区。
- sort: 将R个分区的数据根据key进行排序
- combine(可选): 相当于在map任务中提前进行reduce,目的减少分区文件大小,减小map到reduce传输数据的成本。
Reduce阶段:
- copy: 启动多个线程从map端主动拉取属于自己的那份数据,落到磁盘。
- merge: 合并从map端拉取过来的数据,将磁盘中的多个文件合并为一个文件。
- output: 最终生成一个文件,shuffle阶段结束。
- reduce: 读最终生成的文件,进行reduce操作,得到最终结果。
注意事项
- 图中的一个个数据块仅代表逻辑分布,不代表物理分布。比如map阶段最后生成只会一个文件,同时有一个索引来表明各个分区数据在文件上的位置。
- map、spill、copy这些过程的某些操作中,并不是串行执行的,中间会一个叫做环形缓冲区的东西,你可以将它当做是一个生产消费的队列,只不过消费者只有当队列中的数量达到一定的阈值后,才会进行消费。
文章作者 libra
上次更新 2022-03-23