Elasticsearch的查询原理(中)

文章目录
BKD Tree范围查询
BKD树是BSP(Binary space partitioning)树家族中的一员,大部分BSP树常用于图像渲染等业务中,也有部分BSP树用于多维数据的检索,下面简单介绍一下常用于检索的BSP树。
KD Tree
KD Tree(k-dimensional tree),对外表现为像是一颗二叉搜索树,只不过每一个节点可以存储k维数据(k >= 1),每个非叶子节点可以被隐式的认为生成了一个分裂的超平面,平面左边的节点由左子树表示,平面右边的节点由右子树表示,具有很强的范围查询的能力。
- 3维KD树抽象图
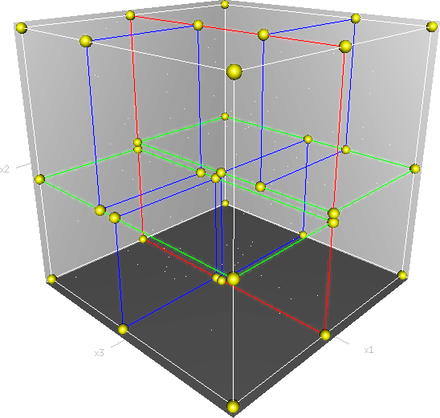
以构建2维KD树为例,需要构建的数据为[(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)]。
根据树的层数,来决定使用第几维数据作为取中位数的元素, axis = depth % k,比如当前为2维KD树,第一层使用第一维元素,第二层使用第二维元素,第三层使用第一维元素…
-
KD树
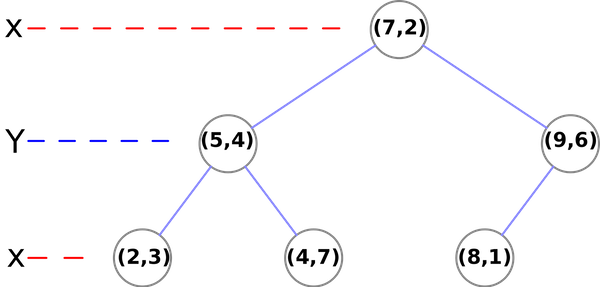
-
抽象出的空间
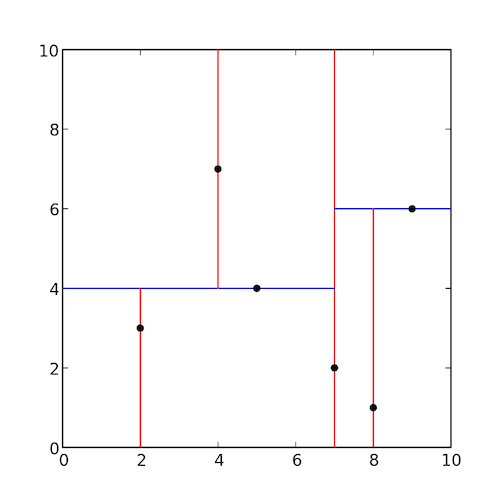
由于存储了多维数据,树平衡算法在KD树上不适用,导致新节点的插入和更新时使得树变得不平衡,只有重新构建树才能使树平衡。
KDB Tree
KDB Tree(k-dimensional b-tree) ,其实就是KD树和B+树的结合,提供平衡KD树检索效率,同时提供B+树的面向块存储的能力以优化外部存储器访问。
- 二维KDB树抽象图
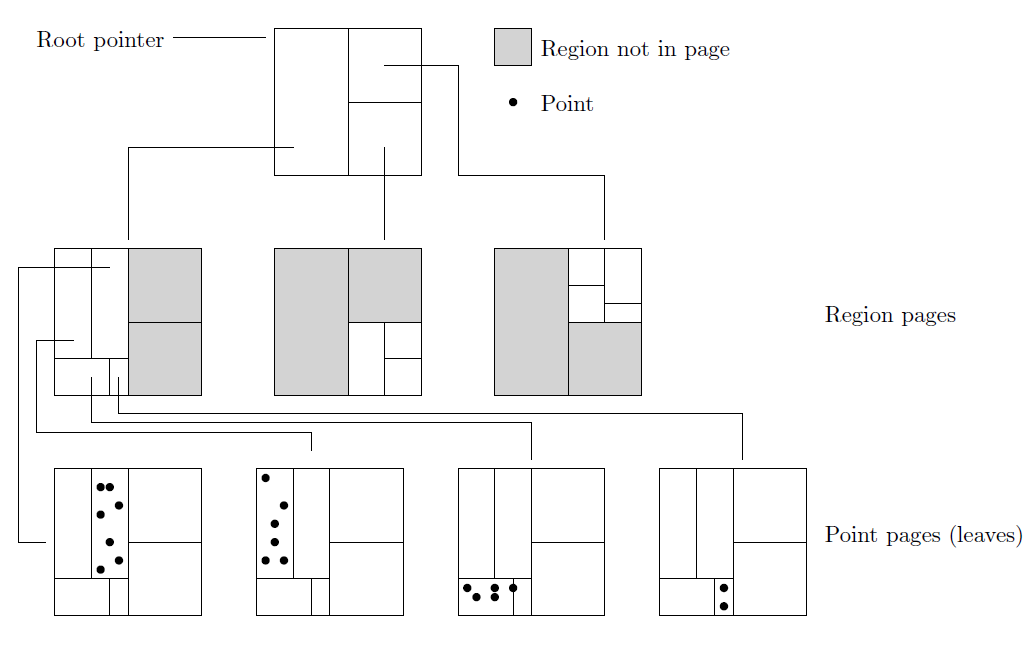
KDB树和B树有类似的结构,每个超平面由左右两个平面分成了多个平面,树的深度变小,同时采取块存储,每个节点块存储更多的数据,如果基于磁盘进行检索,可以大大减少扫描磁盘的次数。
当增删改数据,需要调整树的结构时,太过于复杂,耗时比较高,会导致出现很多空块,进而也会导致存储利用率不高。
BKD Tree
一个动态可扩展的KD树,BKD树保持了静态KDB树的高存储利用率和查询效率,同时还支持更新IO高效。
刚开始我以为,Lucene由于本身segment不可变,刚好符合了KDB树的特性,Lucene会定期merge segment,BKD就是一个能够高效merge KDB树的树,刚开始看论文介绍部分,我以为是,看到后面的实现时,发现不是,到现在其实还有些迷糊。
BKD树不是维护一颗需要在数据更新时进行平衡的树,而是维护了一组的KDB树,通过定期重组这一组树来执行更新(应该是定期merge,而且KDB树不全是上面的那个KDB树,这里纠结了好久)。
BKD树包含一组平衡的KD树,每个KD树类似于KDB树一样在磁盘中存储,为了存储KD树在磁盘上,我们让每个叶子节点存B个点,这样,数据点被存储到N/B个块中。为了存储KD树的内部节点,我们执行以下的算法,设Bi为一个块中适合的节点数,Bi为2的某个正整数幂,首先假设N/B是Bi的一个精确的幂,这样的话内部节点能够很简单存储在O(N/(BBi))个块中。
上面两段话是对论文部分内容的翻译,上面的"KD树"是指一个新的KD树变种,之后文章中提到的"KD树",都是指"KD树"的变种,这种KD树是完全二叉树和B+树的结合,下面我们来看一下它在Lucene是如何实现的(我之前用论文的方法实现, 发现了一堆bug, 可能是我对某些英文单词理解的不够准确?)。
- 指定存储数据块的最大存储大小B。
- 先对所有值进行排序。
- 假设当前需要进行切分的值有P个,取前P/2(向上取整)个值,放到左子树,剩下的值放到右子树。内部节点并不存储数据,只存作为分割点的值。
- 对每个子树重复2,3步骤。
- 当需要切割的值的数量小于等于B时,块作为叶子节点存储。
以一维数据作为例子,假设,我们一共要存2000个值[1, 2, 3, 4, ..., 2000],每个block最多可以存260个值(B为260),KD树如图所示。
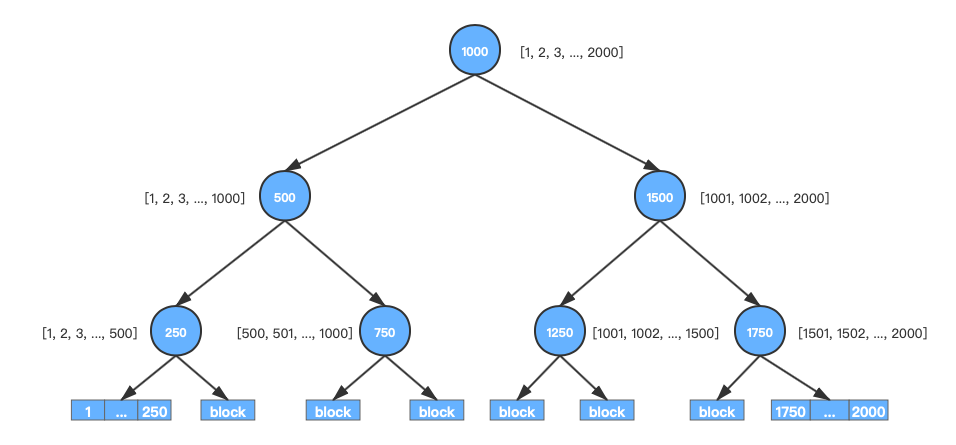
这样我们可以得到一颗满二叉树,但最右边叶子节点可能会存不满,但也接近于100%的空间利用率。
因为是一颗满二叉树,所以我们可以用2n+1和2n+2去定位左右子树,而且内部节点不存储数据,我们完成可以把除叶子节点外的所以节点用更高效的数据结构放到内存中去,以提高检索定位到块的速度。
最关键的是以这样的结构去存储KD树,可以提高两颗KD树合并的速度,这也是BKD树能动态平衡的原因,KD树的不可变性没法改变,那就提高两颗不可变数据结构合并的速度,关于合并的算法,这里不展开讲了,去翻论文和代码吧(- . -)。
检索结果的合并
前面讲的索引结果合并都是跳表与跳表之间的合并。那么BKD树检索得出的结果,会重新写入一个数据结构(数组或位图等),只要我们这个重新构建的数据结构是有序的,那么自然可以用之前跳表合并的方法进行合并,逻辑是类似的。
倒排索引范围查询
DFA算法,这个以后会补上。
检索结果排序
在老版本的Lucene中,会将所有命中的doc数据全部拿到后,再取字段进行排序,这样效率很低。Lucene在新版本中引入DocValues,对字段进行列式存储,通过doc_id在DocValues中能快读取到对应字段,从而进行排序。
Lucene的排序过程:
- 根据查询的from、size参数,构造出一个大小为
from+size的堆。 - 遍历所有命中的doc_id,通过DocValues取到需要排序的字段,维护这个堆。
因为from+size不会特别大,维护堆的内存成本不高,而且读DocValues的性能很高,所以Lucene排序的性能也就很高。
结语
BKD树这一块的东西真的磨了好久,其余大多数的东西也都是不求甚解地去看的,不会扣地特别细,Lucene在代码实现中,基于这些数据结构又做了很多的细节上的优化,有兴趣的大哥们可以自己去扣源码哈,这里就不展开,因为我头快秃了。下一篇会简单介绍一下Elasticsearch多分片多副本的查询原理。
引用
文章作者 libra
上次更新 2021-10-31