Elasticsearch的查询原理(下)

文章目录
多分片查询
es查询分为两个阶段"query"和"fetch",称为"query then fetch"。
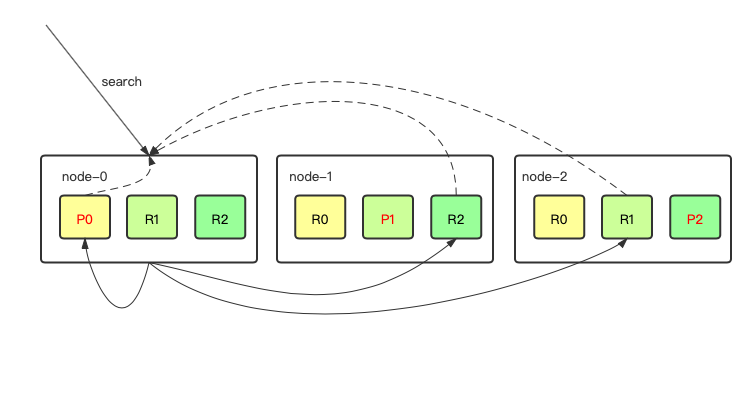
query阶段
- 客户端向node0发起了一次search请求,开始query阶段。
- node0从9个分片中随机选择3个分片,向这3个分片发起search请求,这3个分片需包含全部数据。
- 这3个分片执行查询和排序,返回
from+size个doc_id和排序值。 - node0对三个分片返回的数据进行排序整合,得到
from到from+size的doc_id。
fetch阶段
- node0根据doc_id向相关的分片发生获取文档详情的请求。
- 相关分片返回数据到node0。
- node0拼数据,返回给客户端。
在es中,单分片query的效率是非常高的,但在多分片查询中,需要对来自多个分片的排序值执行排序,值的数量为分片数*(from+size),分片数越多,from+size越大,查询效率越低。比如索引有500个分片,当需要展示第4900到第5000条的数据时,我们就需要对250w(500*5000)条数据进行第二次汇总排序,会占用非常多的系统资源,是具有"深度分页"的性能问题的。
search after
“search after"可以使用上一页的检索结果来检索下一页的数据,从而避免深度分页的问题。
当前进行一次"search after"检索时,首先需要指定检索结果基于哪些字段进行排序,当进行完一次检索后,保存该次检索结果最后一条数据的排序字段,在进行下一页检索时将该值传入"search_after"参数中。
进行search_after检索过程中,所有排序字段都需要有docValues索引且组合起来不能重复,进行翻页操作时,要保证筛选条件和排序条件不变;只可以进行"下一页"操作,不可以进行"跳页”;新版本es可以基于pit接口的索引快照进行查询。
其实,search_after的查询,我们使用range query也可以实现,search_after本身也是这样做的。
search_after其实是利用单分片query的高效率将from变为了0,大大减少了合并多分片排序值的数量。
scroll search
scroll可以来用完成遍历一个索引全部数据的需求,类似于传统数据库里的游标。
其实scroll的原理与search after一致,只不过search_after将"最后一条数据的排序值"丢给了客户端,而scroll将其保存到了es的scroll上下文中。
第一次创建scroll时,会将query、sort、size等字段保存至上下文中,同时做一个数据的当前时间快照,并返回一个scroll_id,之后客户端可以使用scroll_id进行数据的变量,并且在每次scroll的fetch阶段会刷新"最后一条数据的排序值"。
在es的7.15的文档表示,不再推荐使用scroll api用于深度分页,推荐使用search after + pit 进行深度分页。这里是不推荐使用到实时交互的需求中,因为之前没有pit,导致search after不是那么好用,会有部分用户会用scroll代替search after。
结语
Elasticsearch就到这里吧,以后遇到啥坑,再补充吧,现在实战中数据量小,也没啥坑能遇到(- . -)。立个大的flag,下一阶段坚持写完"维度建模"系列文章。
文章作者 libra
上次更新 2021-11-06