Elasticsearch的查询原理(上)

文章目录
粗略整理了一下Elasticsearch查询的原理, 这一篇主要是关于Elasticsearch单分片查询的原理, 由于Elasticsearch单分片查询基于Lucene, 大部分原理与Lucene查询一致, 所以以Lucene作为第一视角, 有不对的地方希望指正。
本文将在以下几个方面进行梳理Lucene(es单分片)的查询原理:
- Lucene中重要的索引结构?
- 什么是倒排索引?
- 在Lucene中是如何存储倒排索引的?
- 在Lucene中如何基于倒排索引进行检索?
- 在Lucene中如何进行范围查询?
- 多个索引得到的结果如何合并?
- 如何对检索结果进行排序?
Lucene的重要的索引结构
- Inverted Index: 倒排索引,用于字符串等数据的索引。
- BKD-Tree: 顺序存储,类似于B树,用于数值、日期、经纬度等数据的索引。
- DocValues: 正排索引, 列式存储。
- Store: 文档原始数据内容。
什么是倒排索引?
假如我们有如下的数据:
| doc_id | name | sex | age | company |
|---|---|---|---|---|
| 1 | Libra | M | 26 | Douding |
| 2 | Tom | M | 25 | |
| 3 | Tony | M | 26 | |
| 4 | Tony | M | 24 | |
| 5 | Lina | F | 25 |
将其使用"倒排索引"进行索引,如下所示
-
name字段索引
term posting list Libra 1 Tom 2 Tony 3, 4 Lina 5 -
sex字段索引
term posting list M 1, 2, 3, 4 F 5 -
company字段索引
term posting list Douding 1 Google 2, 3 Facebook 4, 5
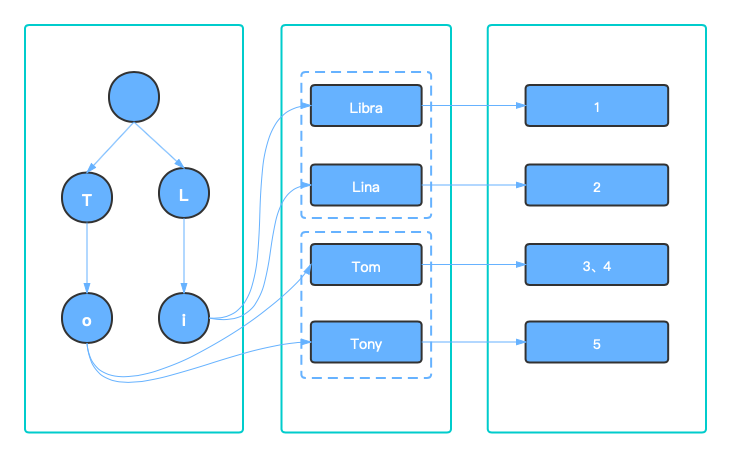
相反于一个文档记录了哪些值的正排索引,倒排索引从值出发,记录一个值在哪些文档中出现过,也就是记录了一个值对应文档的反向列表。term那一列称为字典(term dictionary),每一个term对应的文档列表,称为倒排列表。
当需要查询name = Tony的文档时,只需要在"name字段"的词典中找到"Tony"这个term,从而就找到这个term对应的文档id列表了。
词典索引: FST
如何快速地从词典中找到对应的term,先来看一下一些可以用来存词典的数据结构。
- 有序列表,使用二分查找进行定位term的位置,时间复杂度为O(logN),在term很多时,内存占用过多。
- 哈希表,时间复杂度为O(1),查询效率高,但内存占用比有序列表更多。
- B Tree,基于磁盘的检索,空间大,速度不够快。
- 跳表,占用内存小,时间复杂度接近O(logN),不支持前缀匹配,Lucene3.0之前使用该数据结构存词典。
- FST(Finite State Transducer),内存占用低,支持前后缀匹配,查询快,时间复杂度O(len(term)),但输入要求有序,不容易更新,Lucene3.0之后的版本基于此数据结构存储词典。
我们基于name的词典,来看一下FST的构建的过程,首先先对name的term进行排序,依次将"Libra"、“Lina”、“Tom”、“Tony"插入。
-
插入"Libra”

-
插入"Lina"

-
插入"Tom"

-
插入"Tony"

以上便是构造一个FST的基本流程,关于FST更详细的内容,可以通过关于Lucene的词典FST深入剖析、FST论文、在线构建FST演示深入了解,这里就不详情展开讲了,我们可以不求甚解地认为FST是一个省空间且支持前后缀匹配的hashmap。
即使使用了FST去存储词典,也并不是把每一个Term都插入FST中,FST的终点边指向一个个block,这个block中会有多个前缀相同的term。
当查询某个term时,首先在FST匹配到前缀,拿到对应的block,去扫这些block中所有的term进行比较,最终得到这个term对应的倒排链,如图所示。
倒排链
首先,Lucene中倒排链是基于跳表去存储的。
单条件的查询,其实使用基于数据库的非聚集索引,也是可以做到快速检索的,Lucene常用于复杂条件的检索和全文检索,那基于多条件的检索,Lucene是如何去做的?
交集
假设我们需要查询name = 'Tony' and sex = 'M' and company = 'AWS'的文档:
-
分别找到
name = 'Tony'、sex = 'M'、company = 'AWS'三个条件分别对应的倒排链。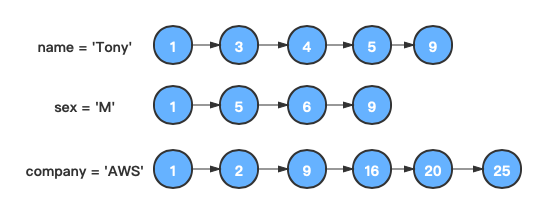
-
根据倒排链的长度进行正序排序。
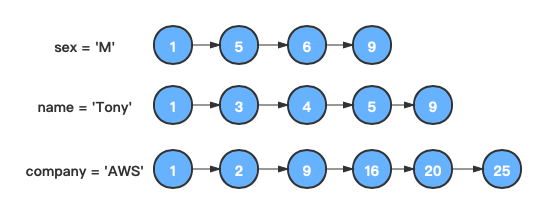
-
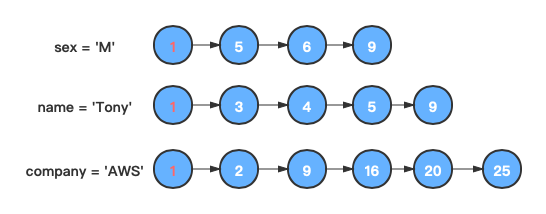
首先找到前两个链表中值相等的节点。
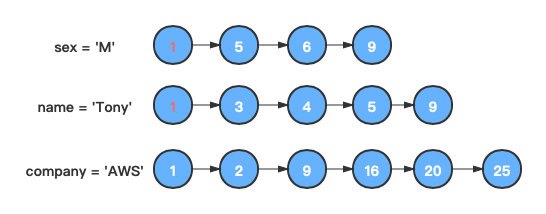
-
根据这个节点的值在剩下的链表中寻找与之相等的节点,如果在剩下的链条中都找到该值的节点,说明该文档符合全部筛选条件。
-
在第一个链表的下一个节点重新进行1步骤,得到值相等的节点"5"。
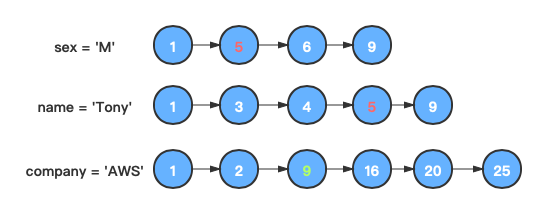
-
如果在剩余任一链表中,发现大于等于"5"的第一个节点为"9"。
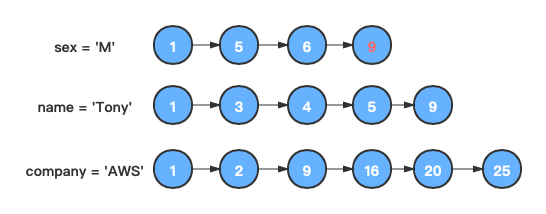
-
则第一个链表跳到大于等于"9"的节点上,重新进行1步骤。
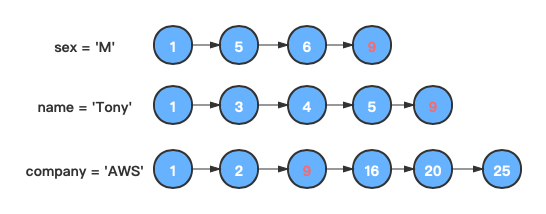
-
第一个链表走完了,合并结束,找到符合条件的文档ID为
[1, 9]。
倒排链求交集的Lucene中部分源码,源码地址。
并集
假设我们需要查询name = 'Tony' or sex = 'M' or company = 'AWS'的文档:
- 分别找到
name = 'Tony'、sex = 'M'、company = 'AWS'三个条件分别对应的倒排链。
-
将三条链表放到以链表第一个doc id作为的标识的优先队列里。
-
每次取出第一条链表中的第一个节点的doc id, 并调整链表的优先队列,累计计算doc_id的出现次数,当前doc_id不再出现时,比较出现次数是否大于等于minShouldMatch(默认为1)。
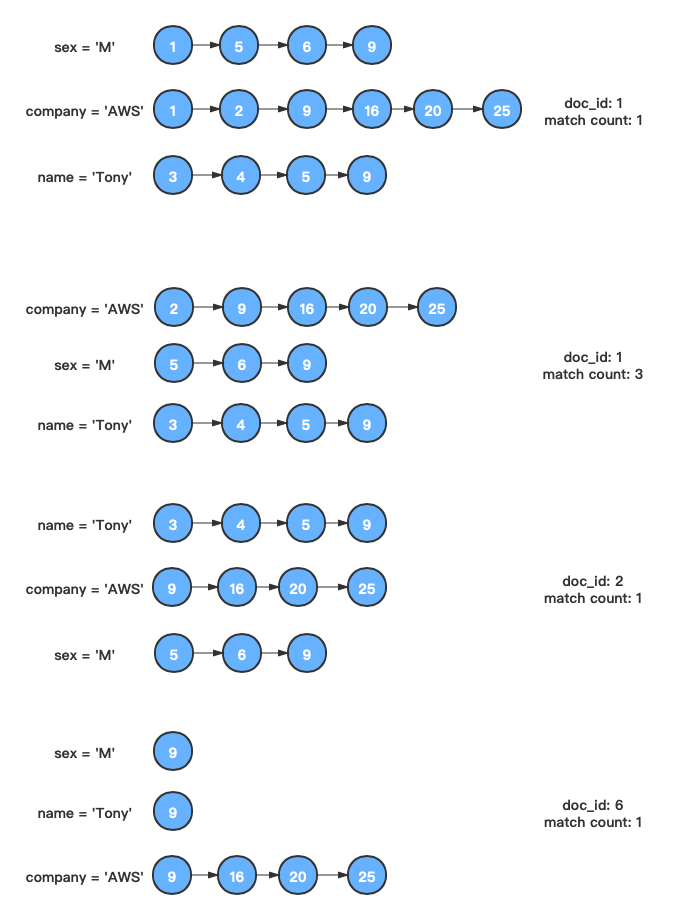
- 直至所有链表的所有节点遍历结束。
倒排链求并集的Lucene中部分源码,源码地址。
差集
假设我们需要查询company = 'AWS' and name != 'Tony'的文档:
-
分别找到
company = 'AWS'、name = 'Tony'两个条件分别对应的倒排链。 -
过程比较简单,遍历不需要做差的链表,每遍历一个节点,用该节点的doc_id,去需要做差的链表,没找到则保留。
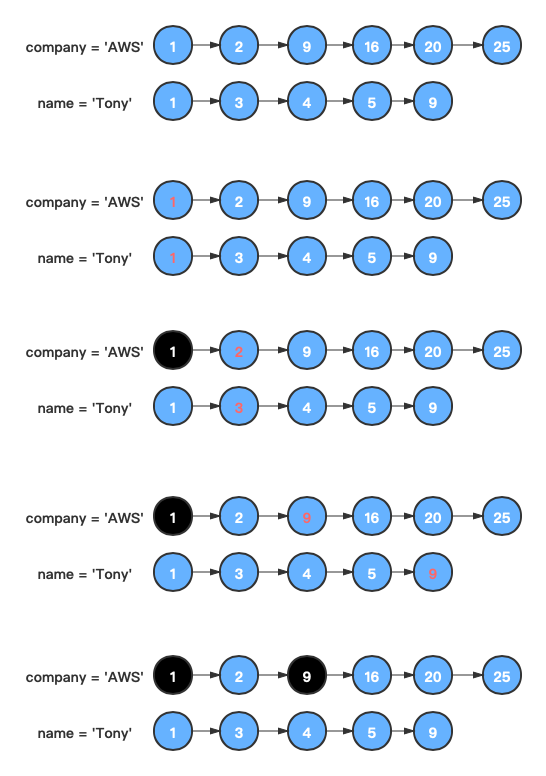
倒排链求差集的Lucene中部分源码,源码地址。
结语
半包装修好麻烦呀,做图好烦呀,本来想写上、下两篇的,结果一篇拖了三周,所以我打算拆成三篇来写,要不然又要半途而废了。
BKD树、索引范围查询、检索结果排序,将在下一篇写。
参考
文章作者 libra
上次更新 2021-10-27