简单了解一下列式存储

文章目录
就当抄书了,还是不好好抄书的那种。
什么是列式存储?
在我们经常接触的OLTP数据库(如Mysql、Mongodb),大多是使用行结构进行存储数据的,当我们需要查询数据表中某些实体的数据时,我们可以通过一次索引就可以找到这个实体所有相关的数据,因为这个实体的数据都被存储在一行中的,这在OLTP的业务中是很顺其自然的一件事情。
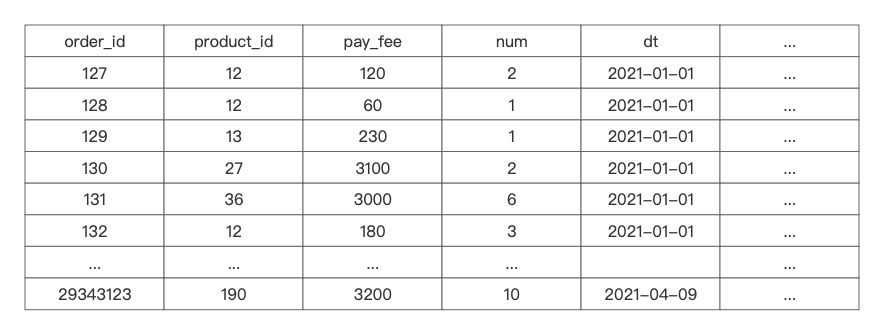
基于如上订单表,order_id为该表的主键,使用Mysql存储,当完成"查询order_id为127的订单的所有数据"需求时, 数据库可以直接在聚集索引中直接拿到该订单所有字段的数据。
|
|
但我们需要完成"统计在2021年1月1日各个产品的总销售额和总销售量是多少"时,假设"dt是二级索引",我们通过dt的二级索引找到对应的聚集索引,但由于数据是使用行结构去存储的,我们需要将一行行数据全部从磁盘中拷贝到内存中,再从这些字段过滤出我们需要的字段去进行聚合操作。
|
|
列式存储,不同于行存储将一行中的数据存储在一起,列存储将属于同一列的所有值存在一起,每一列的值分别存为不同的文件,当我们进行查询和聚合时只需要根据需求,去往不同的列文件去读取对应列的数据,可以大大减少拷贝的数据量,加快数据读取的过程。
基于列式存储的文件
- order_id: (127,128,129,130,131,132,…,29343123)
- product_id: (12,12,13,27,36,12,…,190)
- pay_fee: (120,60,230,3100,3000,180,…,3200)
- num: (2,1,1,2,6,3,…,10)
- dt: (2021-01-01,2021-01-01,2021-01-01,2021-01-01,2021-01-01,2021-01-01,…,2021-04-09)
列压缩
除了通过仅加载需求所需列来减少磁盘的吞吐量外,还可以通过对数据进行压缩来达到相同的目的,列式存储非常适合进行数据压缩。以下介绍的是 C-Store 中的数据编码方式。
我们根据两点来决定,数据适合使用什么样的编码方式。
- 数据排序是否有序
- 数据中有多少不同的取值
以下为四种不同的情况。
- 有序且不同值少。可以使用三元组
(v,f,n)对数据编码,表示数值v从f行出现,一共有n个。例如(1,1,1,1,2,2,2,3,4,4,4),可以表示为((1,1,4),(2,5,3),(3,8,1),(4,9,3))。 - 有序且不同值多。可以把每个数值表示为前一个数值加上一个变化量。 例如(1,8,13,14,29,30),可以表示为(1,7,5,1,15,1)。
- 无序且不同值少。可以对每一个取值构造一个位图索引。例如上表中product_id列(12,12,13,27,36,12,…,190),可以表示为(12, 110001…0),(13, 001000…0),(27, 000100…0),(36, 000010…0),(000000…1)。
- 无序且不同值多。 对于这种方式没有很好的编码方式。
编码之后,可以将数据进行压缩。由于一列中的数据本身具有相似性,即使不做特殊编码,也能取得很好的压缩效果。
列压缩除了可以减少从磁盘中加载的数据量,还有利于高效运用cpu周期,当我们列进行压缩后,我们甚至可以将一大块压缩的列数据放入CPU L1级缓存,进行紧凑地快速迭代计算。
列存储的排序
单独排序每列数据是没有意义的,会导致多个列文件的数据顺序不一致,多个列文件根据行顺序决定多个列是否属于同一行。
列存储的写操作
使用B-Tree进行原地更新的方式是不可能的,大多数OLAP数据库、搜索引擎,都是采用LSM-Tree类似的方式,先写入内存,在内存中累积一定的写入数据,落磁盘,与旧的磁盘文件合并,生成新的磁盘文件,删除旧的文件。只能追加式更新文件,已经生成的磁盘文件不会被修改,只能被合并后完全被删除。
结语
最近好闲呀。
引用(抄)
文章作者 libra
上次更新 2022-03-22